- Blog
Discovering Causal Drivers at Scale





Executive Summary
For high-quality enterprise decision making, it’s crucial to have effective methods for discovering cause-and-effect relationships within data. A significant number of business decisions require understanding cause-and-effect across a large number of variables. As such, scaling causal discovery, so that it works for high-dimensional datasets, is one of the key challenges within the field of causality.
Algorithms for causal discovery have advanced significantly, and can effectively reveal causal relationships in datasets with a moderate number of dimensions. However, as the number of relevant variables increases, the required computation grows at a super-exponential rate. The scientific community has demonstrated that discovering causal relationships using purely observational data is an NP-hard problem.
causaLens has productized four approaches that greatly increase the scalability of causal discovery, demonstrating an order of magnitude increase in the number of variables for which it can be performed compared to algorithm-only approaches. These are:
- Taking a coarse-to-fine approach
- Optimizing hyperparameter selection
- Embedding more domain-knowledge
- Searching locally
This article will outline how these approaches allow causal discovery to be scaled and why decisionOS by causaLens is the fastest way to implement these techniques.
Introduction
The biggest challenge in causal discovery is overcoming the size of the data search space. As data-driven approaches are applied to increasingly complex business challenges, with larger quantities of relevant data, the time required to discover causal relationships grows super-exponentially. The problem becomes increasingly difficult to solve and eventually intractable. As organizations collect more and more data, solving this challenge becomes even more crucial.
Discovering an entire causal graph algorithmically across a large number of variables is infeasible due to the NP-Hard nature of the problem. So, while algorithmic causal discovery is a key part of the overall causal discovery process, it needs to be used in tandem with other techniques for high dimensional problems. Each of the techniques outlined in this article takes an orthogonal approach to narrowing down the overall search space.
Taking a Coarse-to-fine Approach
The first approach involves carrying out a coarse, high-level causal search across clusters of variables and then drilling further down into selected clusters when greater resolution is required. With the coarse-to-fine approach, the search space is narrowed by creating higher-order clusters rather than using individual variables, before carrying out increasingly fine, more computationally intensive causal discovery.
As an example, for a million column data set, columns could initially be grouped into, e.g., five clusters of 200,000 variables each. These clusters would be defined based on clustering methods of choice, this may involve using distances for high-dimensional data and/or, based on domain knowledge from the user.
Next, a complex, but computationally light transformation can be used to summarize each set of 200,000 variables into a single, new variable. Algorithmic causal discovery can then be run for all five of the new, ‘transformed’ features to understand the relationships between clusters.
For the clusters which are of particular interest, a data scientist can then dive deeper to better understand causal relationships at a finer resolution. This could be at the sub-cluster or individual variable level. This process then repeats until we have a causal graph of transformed features which we can use to build a causal model. This process is shown in Figure 1.
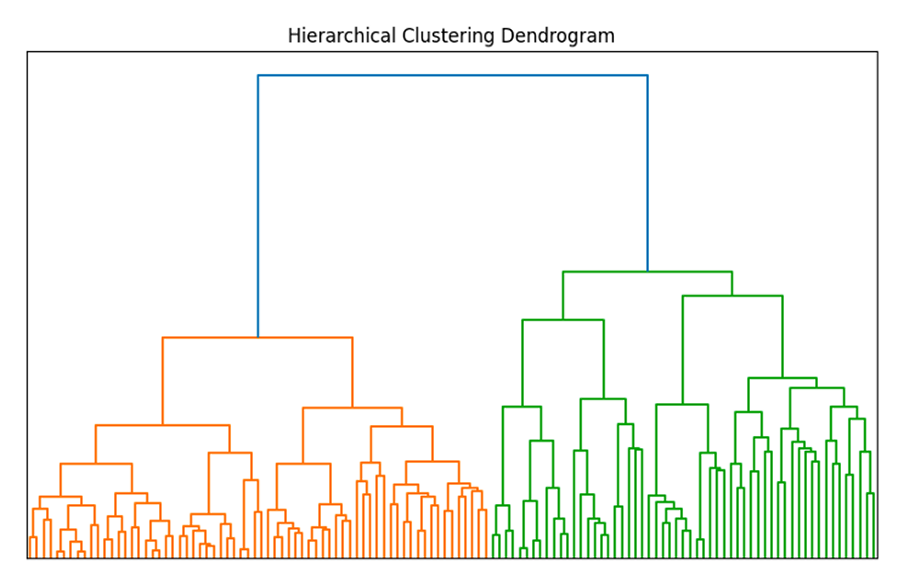
decisionOS by causaLens is able to guide data scientists through the entire coarse-to-fine approach. It can help with initial cluster selection, indicate which clusters contain the most signal and finally assist with selection and application of the most appropriate causal discovery algorithm.
Optimal Hyperparameter Tuning
A second approach to speeding up causal discovery is to select optimal hyperparameters when carrying out algorithmic causal discovery. In many cases, the selected hyperparameters define how much of the search space needs to be traversed when using score and constraint-based techniques to uncover causality. By setting these at appropriate levels, the search space can be reduced while maintaining accuracy. Important hyperparameters for causal discovery can, for instance, include:
- P-Value Thresholds
- Oracles
- Maximum Path Length
- Maximum Separation Set (Sepset) Size
- Maximum Parent Set Sizes
Adjusting hyperparameter values to reduce search time naturally reduces the comprehensiveness of the search. There is a danger of performance degradation if the trade-offs, which the data scientist is required to make across all of the specified hyperparameters, are not chosen effectively. With decisionOS, guidance is provided as to when it is sensible to make a trade-off between hyperparameters, based on extensive benchmarking research carried out by causaLens.
For example, in Figure 2, causaLens has shown how, for a given problem, the average running time is inversely related to the maximum separation set size and the maximum path length (see left column in the figure). The impact of the maximum path length and the maximum separation set size hyperparameters are higher for dense graphs (bottom row) than for sparse graphs (top row).
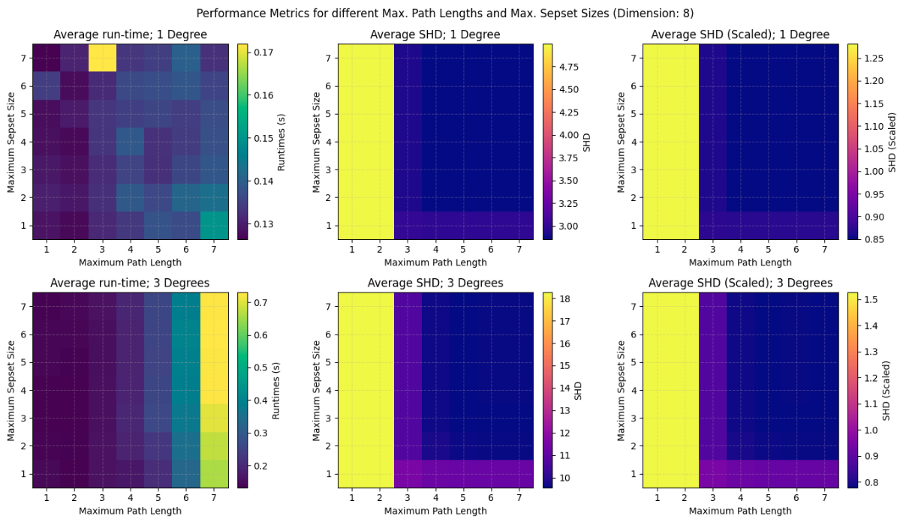
It is important to note that the maximum path length parameter has a dramatic effect on the Structural Hamming Distance (SHD) (lower is better), as can be seen in the middle and right columns. For this parameter, the results imply that, for 8 dimensions with an average degree of 3, it would be detrimental to select a low value of the maximum path length parameter. In this instance, the search space has been reduced too much.
In contrast, the maximum separation set size parameter does not seem to have much of an impact on the overall SHD. This is, therefore, an area where significant gains can be made in causal discovery computation time while maintaining the required accuracy levels.
decisionOS provides clear guidance on hyperparameter selection such that a good set of trade-offs between running time and accuracy can be made. causaLens significant research into scaling causal discovery methods through optimal hyperparameter selection is reflected in the product capabilities.
Embedding Domain-knowledge
Embedding domain-knowledge into causal models is another effective way of reducing the search space for causal discovery. It also has the added benefit of allowing knowledge, which may be difficult to measure, to be included in the causal graph.
Domain knowledge can be included in the causal discovery process in two ways. The first approach is for an expert to define relationships between different nodes. This may involve defining the exact functional relationship. However, it can also be as simple as specifying that there is a causal relationship between two nodes but its form is unclear, or that a relationship does not exist.
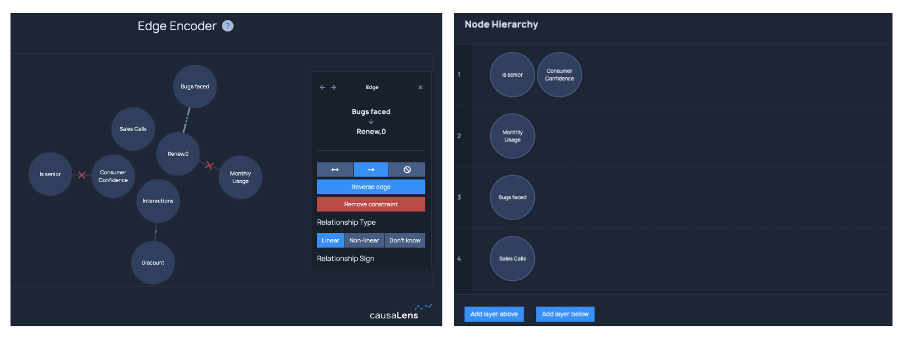
The second approach involves an expert defining knowledge in a causal hierarchy of variables or ‘tiers’. In this approach, the hierarchy defines which nodes may have a causal influence on others. Nodes in a particular tier are only causally influenced by nodes in their tier or higher tiers. For example, In Figure 3 we can see that the ‘Is Senior’ variable, which captures a customer’s age, is at the top of the hierarchy as it is an exogenous variable.
It is intuitive that the inclusion of domain knowledge into a model will improve performance and increase scalability. But the extent to which it helps is surprisingly large and as such, when available, this is an approach that should be used. This is highlighted in causaLens work incorporating domain-knowledge into the A* causal discovery algorithm. The results showed that, for a given problem, domain-knowledge can reduce discovery time by >50% with no loss in accuracy.
Including this domain knowledge is very powerful, but can be difficult to capitalize on without the right tooling solution. Close collaboration is required between data scientists and knowledge experts in the organization and it is crucial that domain knowledge is reflected accurately in the modeling work. Transferring knowledge between these parties is often challenging, particularly in large organizations, so often this valuable domain knowledge is left out of data science models.
causaLens has tackled this problem head on with the Human-Guided Causal Discovery app within decisionOS. This allows data scientists and domain experts to seamlessly collaborate to include domain knowledge within causal models, without interrupting the data science workflow.
Searching Locally
There are times when full causal graph discovery is not necessary to solve a particular problem and it may be the case that only the local structure around a variable of interest is required. For example, if the requirement for a model is to predict a single variable, identifying the local causal structure around this variable is sufficient to build an effective model. If done correctly, the resulting model will generalize sufficiently well.
So, in this case, the search space is being narrowed by discovering the causal structure around the variable of interest rather than attempting to discover the full causal graph. For this to work, it is important to ensure that the data is configured correctly so that (conditional) independence does in fact indicate that there is no causation. The required assumptions for this to be the case are:
- Causal Markov Condition
- Causal Faithfulness Condition
- Causal sufficiency
When these assumptions are combined, “two [random] variables are directly causally related if and only if they are not conditionally independent given any subset of the remaining variables.” Lu et al. Crucially, this subset can be the empty set.
Therefore, if two variables are measured as independent, i.e., conditionally independent given the empty set, it is safe to conclude they are not directly causally related. Any covariates that are independent of the target variable can then be removed.
Once a sufficient number of covariates have been removed from the dataset, algorithmic causal discovery techniques can be used to discover the parents of the target variable and thus the ‘local causal graph’. This method works with all three categories of causal discovery algorithms: constraint-based, score-based, and continuous optimization methods and has been shown to reduce the number of potential parents by up to three orders of magnitude.
decisionOS allows local causal discovery parameters to be easily specified and the most appropriate causal discovery algorithm to be applied to a given problem. causaLens has applied local causal discovery to a range of business challenges with excellent results, all facilitated by the capabilities of decisionOS.
Conclusion
Taking a more informed approach to causal discovery can significantly widen the pool of business challenges which can be addressed with a causal approach. Each of the techniques specified above should be used, in tandem when appropriate, to scale causal discovery.
decisionOS by causaLens simplifies use of these techniques offering the simplest, fastest solution for scaling causal discovery. causaLens has significant experience applying these techniques to a range of business challenges which is reflected in the product capabilities.