- Blog
Enterprise decision making needs more than LLMs





Large language models are taking the world by storm thanks to the success of ChatGPT. Its success is undoubtedly remarkable: it’s helping everyone – teachers, students, developers, salespeople – every day there seems to be a new use-case which highlights another profession that can be completely transformed thanks to the use of LLMs.
Another change which hasn’t been so much covered has been in using LLMs is the appearance of tools and agents. This way of using LLMs, which is slowly gaining notoriety thanks to AutoGPT, LangChain and ChatGPT Plugins, consists of enabling it to act as intermediaries between users and a set of tools: for instance, booking a restaurant, making a google query, or loading data from a server and inspecting it.
The reason why this is an important use-case is because ultimately LLMs are limited in what they can do and what they know – so providing an extra pair of hands and a library that can be accessed is a handy way of exploiting their communication skills in order to improve the user experience of certain tasks. These approaches have their own set of limitations: while LLMs are good at learning and extracting information from a corpus, they’re blind to something that humans do really well – which is to measure the impact of one’s decisions.
When it comes to enterprise decision making, there’s an extra price to be paid in using LLMs, and that is privacy. Ultimately companies that rely on the large providers (such as OpenAI) are forfeiting their own intellectual property whenever they make a query on LLMs – the applications that need them the most – which involve sensitive and hard decisions – are those most at risk of leaking important and proprietary information.
Many organizations are now facing this precise challenge: we can’t really use ChatGPT because:
- It doesn’t understand the context of our problem, we have a lot of internal data which requires slicing and dicing to actually be useful
- It can’t really infer cause and effect relationships within our business context: sure advertising leads to increased sales, but by how much? And what’s the optimal channel to run my ad campaign?
- It can’t really suggest optimal interventions because it doesn’t know, fundamentally, which interventions can be taken, what their costs are, and how they affect other parts of the business as well.
In this paper, we want to suggest a way forward for organizations to maximally leverage the power of LLMs, while at the same time promoting a scalable data culture that takes the best out of both AI and humans.
LLMs can’t solve problems alone
Let’s take the example above: a large retailer has an ad budget and wants to optimally spend it across different channels. There are many challenges here:
- Are we running the right campaigns? Is the language of our campaigns actually driving conversion?
- Given all the channels that we have – which is the one with the highest return on ad spend (ROAS), which is the one that’s driving the most brand recognition?
- How do we spend our budget across all channels to maximize our objective, which will be a combination of revenue and recognition – while hitting the right demographic as well?
While the first problem – designing the possible sets of ad campaigns – is one that can be outsourced to a chatbot, the latter problems are actually of a different kind. It’s obvious that ad spend leads to revenue, but to be able to make an optimal decision, what we need is to understand by how much exactly each campaign and each channel is contributing to revenue.
This task – attribution of an action to an outcome – is within the realms of causal inference. Something that LLMs aren’t able – at least not on their own – to do. This problem isn’t only important, it’s completely existential to most industries. When margins are low, the difference between a ROAS of 3 and a ROAS of 2 can be success or bankruptcy.
A precise scientific methodology that understands cause and effect relationships from data cannot be outsourced to language models, since their understanding of the world is qualitative: ad drivers revenue. But we know that on their own, they’ll never be able to tell you by how much.
LLMs aren’t trained to make decisions
Making a decision is about evaluating pros and cons, risks and rewards, cost and revenue. This leads us to the counterfactual world: a world of possibilities that haven’t yet happened, but are hypothetical: if I just only buy facebook ads, what will be my ROAS?
Furthermore, by understanding cause and effect relationships and being able to infer “what could potentially happen” in every scenario, not only we are optimizing for a given outcome and making the best possible decision – but we’re also preparing ourselves for the worst that could happen – since we know that the future isn’t always going to be the same as the past.
Decision making is a complex science – and one that has causality at its core. Right now there’s not enough evidence – even in purely qualitative terms – to suggest thatLLMs can correctly infer causality from past events.
But LLMs have great use-cases
While LLMs are fundamentally language tools, they have many applications that really do beyond just extracting and summarizing data. In many of these applications, however, we need Causal AI in order to extract the full power of LLMs.
As an example, take the problem of detecting anomalies in car insurance claims. The problem here is clear – an insurance company is receiving claims, and needs to evaluate whether to automatically approve them, or to investigate whether the claim was fraudulent – someone could be, for instance, conspiring with the service provider in order to inflate the bill.
In this scenario, it’s fundamental to understand the cause-and-effect relationships within the problem: the accident type, the brand of the car, the new parts that need to be ordered, the jurisdiction in which the repair is being done, etc. All of these drive the price of the repairs.
At the same time, there’s a strong idiosyncratic component to every claim, which is best understood if we have a language tool that can read and extract relevant information from the text, standardize it and structure: for example, suppose that this was a vintage car that went through a series of refurbishments – making it more valuable than a new car today.
Fundamentally, LLMs are great for language related tasks: chatting, summarizing texts, extracting relevant information or even aiding humans in understanding complex problems that require a high degree of abstraction.
In tasks in which we need to deal with large amounts of structured information – such as forecasting or inference – we need Causal AI. These tasks, however, offer the biggest opportunity for collaboration between LLMs and causal inference – since we can now use the full power of language models to extract information which would otherwise have been hidden from our analysis. But LLMs alone cannot deal with the issues that Causal AI is built to solve.
Decision making needs humans in the driving seat
In a time where it seems that everything is a possibility for AI, there’s a tendency to believe that ultimately all decision making will be replaced by machines, and humans can take a backseat and just watch the process passively. Much like self-driving cars, however, the devil is in the details, and trust is the ultimate barrier for humans to adopt AI.
What if, instead of relying on AI for black-box decisions – we could have machines that are transparent and explainable from the start – and most importantly, can understand human expert judgment and help make better decisions which adhere to this knowledge? Humans bring a unique perspective to the table, bringing a wealth of experience and knowledge, as well as a deep understanding of how variables – quantitative and qualitative – affect each other.
Making better decisions and becoming better at measuring the impact of our decisions is the next challenge for AI – but for that, we need to be mindful of the challenges in doing so, and it has become increasingly clearer that without a deep understanding of cause and effect relationships and without humans driving the possible, this is an impossible task.
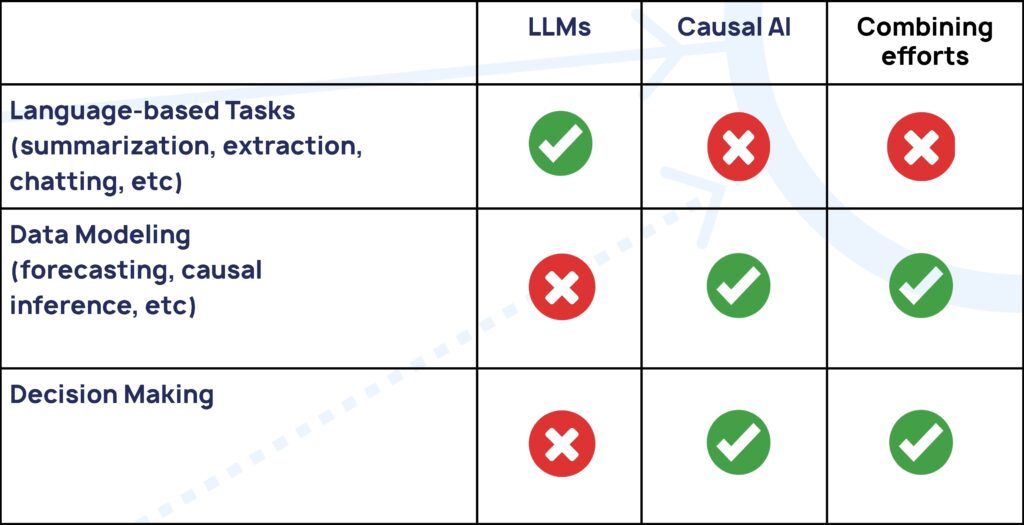
While many applications are promised as use-case of LLMs, in some of them we need to be careful. While LLMs are able to perform these tasks in generic qualitative settings, they’re not able to dig into enterprise data in order to deliver.