- Blog
Confounders: machine learning’s blindspot





Nine out of every ten machine learning projects in industry never make it beyond an experimental phase and into production. One key factor that accounts for this alarming statistic is that machine learning algorithms can’t identify “confounders”.
We explore why blindness to confounders is a big hindrance for AI, before showing why Causal AI, a new category of machine intelligence, is the solution. But first, what are confounders?
What are confounders?
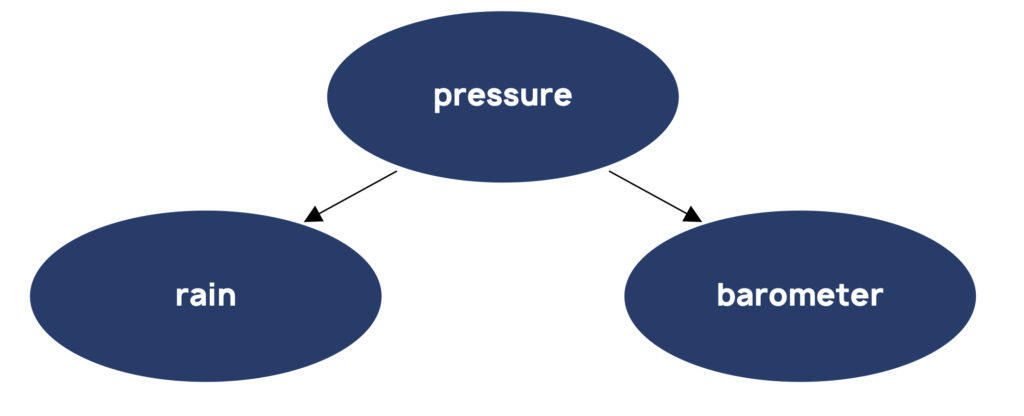
A confounder is a common cause of two or more other variables. For example, air pressure is a confounder of rainfall and the reading on a barometer.
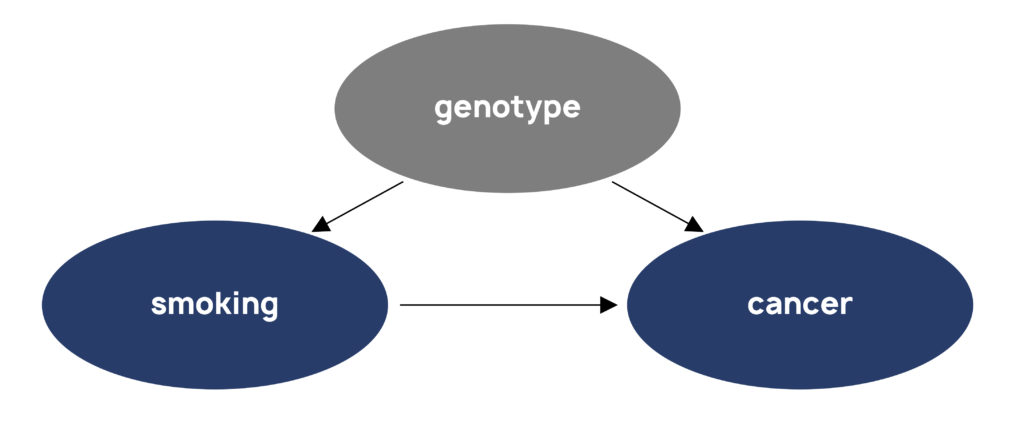
Confounders are often called “lurking variables”, because they can go unknown and unmeasured. For example, we now know that a person’s genes influence whether they start, and become addicted to, smoking. Certain clusters of genes also increase risk of lung cancer. So genotype is an (often unmeasured) confounder of both smoking and cancer.
The English word “confounder” is derived from the Latin confundere, meaning “to mix up”. Confounders mix up and make it difficult to isolate real causal relationships. They also introduce “spurious correlations” between variables that are not directly causally related to one another.
Why is current AI blind to confounders?
Early AI researchers attempted to explicitly code knowledge about the world into machines. But this proved to be extremely challenging. Today’s AI systems generally acquire knowledge on their own — this is known as machine learning.
Standard machine learning algorithms extract patterns or correlations that are buried in raw data. This goes for simple algorithms, like logistic regression, and more sophisticated algorithms, like neural networks, which can learn very subtle patterns from raw data.
You’ve probably heard the phrase “correlation is not causation”. Correlations are symmetrical (if x correlates with y then y correlates with x), they lack direction and they’re quantitative (the “Pearson correlation coefficient”, a standard measure of correlation, is a single number between -1 and 1). In contrast, causes are asymmetrical (if x causes y then y is not a cause of x), directional and qualitative. So correlation and causation are different concepts.
Furthermore, causes can’t be reduced to correlations, or to any other statistical relationship. Causality requires a model of the environment. We know this largely thanks to Turing Award-winning research by AI pioneer Judea Pearl.
Today’s machine learning algorithms are blind to causality and confounding, because they can only see correlations. A machine learning algorithm can identify a pattern between smoking and cancer, that the two variables tend to go up and down together. But it can’t tell whether smoking causes cancer or cancer causes smoking. Nor can the algorithm disentangle the confounding influence of genetics on that relationship.
In fact, many machine learning models are known to be positively biased towards learning confounders, or spurious correlations instead of direct causal relationships.
Why do confounders matter?
There are many reasons why being able to identify confounders matters.
Firstly: predictions. Confounders lead to bad predictions because the spurious correlations they generate tend to hold good only in narrow settings. And so standard machine learning models that absorb spurious correlations found in training data tend to generalize badly to new data. There are many examples of this problem in image recognition (see Figure 3).

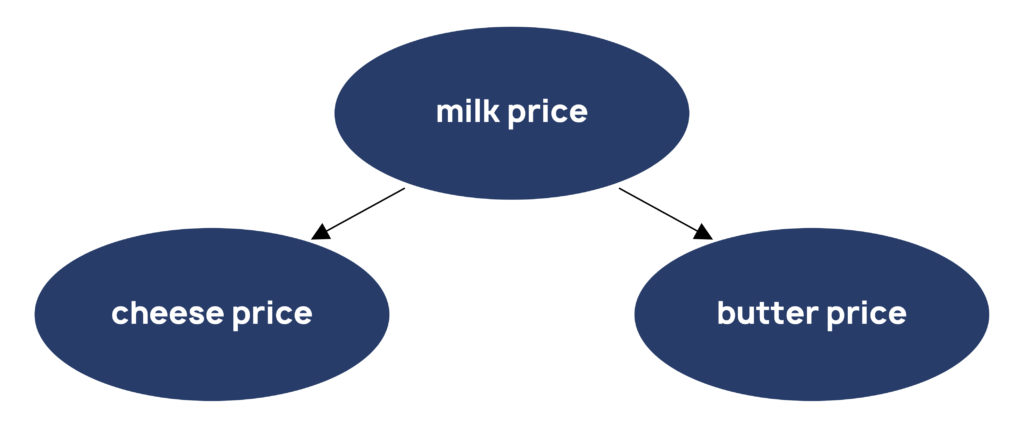
As another simple example, take dairy commodity price predictions. Milk prices drive cheese and butter prices, which in turn are spuriously correlated (Figure 4). An algorithm that learns that butter is a good predictor of cheese prices can come unstuck when that correlation breaks down. A secular shift in consumer purchasing behaviour, changes in stockpiling of the two commodities, or event-driven disruptions to the catering industry, can each differentially impact the two prices.
“The big lie of machine learning” is how Zoubin Ghahramani, a Cambridge Professor and Distinguished Scientist at Google, refers to this assumption that the real-world data is the same as the training data.
Second: selecting actions. Being able to identify confounders is essential for recommending intelligent actions and formulating scenario plans. To find out what happens if you or someone else takes action, you need a “de-confounded” model that separates real causal impact from spurious associations.
The basic point can be illustrated with a simple example from macroeconomics. Mid-twentieth century economists noted a historical negative correlation between inflation and unemployment (Figure 5). Robert Lucas, Nobel Prize winner, pointed out that it doesn’t follow that central banks can reduce the unemployment rate by targeting higher inflation. The reason is that there are lurking variables — such as the monetary policy regime and firms’ inflation expectations — that are responsible for the historical correlation. According to Lucas, if central banks attempted to exploit the correlation, they’d break it.
The implications of AI that can reason about and design intelligent actions are huge for business and financial services. The central questions for many businesses have to do with taking actions: setting prices, allocating resources and innovating new products. Businesses and financial services institutions also need to scenario-plan for different macroeconomic and monetary regimes. Without knowledge of confounders, AI cannot meaningfully assist with these problems.
Third: bias. AI models that learn all spurious associations in a dataset also absorb all the biases that are implicit in that data. Credit decisioning systems are known to profile applicants based on protected characteristics, like race, that are spuriously correlated with unprotected features in the data. Algorithmic bias is becoming an increasingly significant problem, as AI systems grow in power and autonomy.
Causal AI can make more robust predictions, it can evaluate actions and design optimal interventions, and it can help towards de-biasing algorithms — thanks to its ability to distinguish genuine causes from spurious correlations.
causaLens builds breakthrough tech to discover confounders in any data
Causal AI is a new category of machine intelligence that understands cause and effect.
Leading AI researchers agree that causality is the future of AI. “Many of us think that we are missing the basic ingredients needed [for true machine intelligence], such as the ability to understand causal relationships in data”, says Yoshua Bengio, a leading figure in deep learning research.
Causal AI is the only method that can identify confounders in noisy data and distinguish direct causal relations from spurious correlations. This capability solves the problems that confounders typically create for conventional machine learning.
causaLens is at the forefront of developing and commercializing Causal AI.